Part 8. Semantic Roles
By Rodrigo Alarcón, Computational Linguist

In this tutorial of Codeq’s NLP API we will focus on a single module that can be used to extract semantic roles from texts. Previous tutorials of this series can be found here:
- Part 1. Getting started and sending requests to the API.
- Part 2. Calling NLP annotators for linguistic analysis.
- Part 3. Using text classifiers to classify sentiments and emotions, and detect sarcasm in texts.
- Part 4. Detecting abusive and harmful content from texts.
- Part 5. Extracting and disambiguating named entities.
- Part 6. Extracting Speech Acts, Questions & Tasks.
- Part 7. Summarizing texts.
The complete list of modules we offer can be found in our documentation:
Codeq NLP API Documentation
Define a NLP pipeline and analyze a text
As usual, the first step is to declare an instance of the NLP API client and use it to send a text along with a pipeline variable indicating the name of the Semantic Roles annotator. The output is a Document object that contains a list of analyzed Sentences. A quick look of the output can be found with the method document.pretty_print().
Semantic Role Labelling
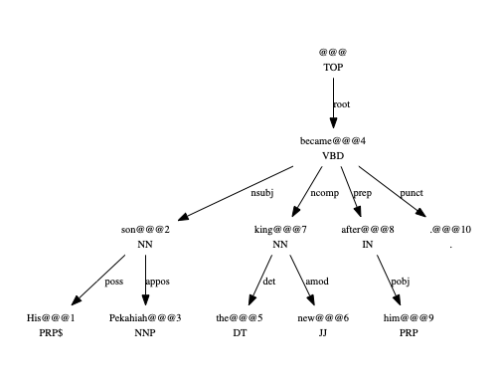
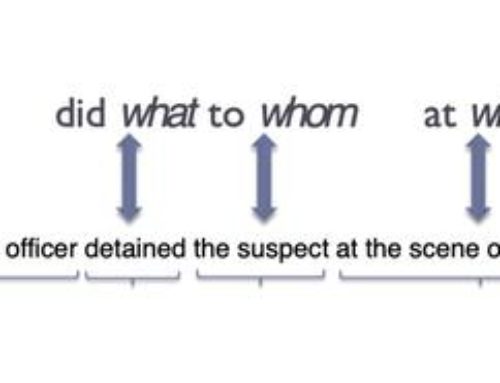
The goal of this module is to identify the main events and participants in sentences and classify the different types of relations between them. In the extraction of Semantic Roles, events are called predicates, while the participants are known as the arguments of a given predicate. Arguments can denote specific types of relations, for example they can be an Agent, a Patient or a Location in relation to the predicate.
More details about the Semantic Role Labeler and an example of its application can be found here:
Exploring CORD-19 with Codeq NLP API and Semantic Roles
- KEY: semantic_roles
- ATTR: sentence.semantic_roles
Output Labels:
- Agent/Experiencer
- Patient/Theme
- Instrument/Beneficiary/Goal
- StartingPoint/Attribute
- EndingPoint
- Location
- Purpose
- Cause
- Temporal
- Modifier
- Negative
- GenericArgument
From the output above we can observe the following:
- All semantic roles contain a predicate and, if present, a list of arguments for that predicate.
- Predicates include the token, lemma (inflected form) and position in the sentence.
- Each argument will contain the type (see Output labels above), the tokens of that argument and the position of the tokens in the sentence.
- All token positions in the sentence start from 1 (instead of 0, as lists in Python).
Wrap up
In this tutorial we described how to use the Semantic Role Labeler of the Codeq NLP API. The code below summarizes how to iterate over its output:
Take a look at our documentation to learn more about the NLP tools we provide.
Do you need inspiration? Go to our use case demos and see how you can integrate different tools.
In our NLP demos section you can also try our tools and find examples of the output of each module.