By David Schueler, Computational Linguist
The ‘ncomp’ dependency label
We at Codeq recently undertook a major revision to the corpus we use to train our dependency parser. We corrected some obvious annotator errors and enforced consistency of conventions of parsing for various patterns. As part of this process we decided to introduce a new dependency label to encode certain relations between syntactic heads and their dependents. The original labels we start from come from De Marneffe et al. 2008; when I mention modifications to the original set of dependency labels in this article, it should be understood as modifications to the system presented in De Marneffe et al. 2008.
The new label is ncomp, which designates a noun phrase complement dependency type. The new label is parallel to the existing labels acomp, which designates adjective phrase complements; and ccomp and xcomp, which designate different types of clausal complements. (It is also reminiscent of the label pcomp, though that label is used a bit differently, to designate certain complements of prepositions, rather than complements which are prepositional phrases, the latter designated by the label prep.) ncomp is used for cases where a noun phrase does not fit into existing dependency types that are used for noun phrases, such as dobj (direct object), iobj (indirect object), or npadvmod (noun phrase adverbial).
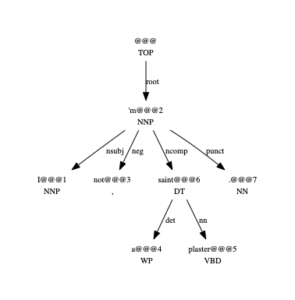
A common instance of the use of ncomp , though not the only one, is to indicate that a noun phrase is the second argument of the verb ‘be’. For instance, in (1), the noun phrase “a plaster saint” forms an ncomp dependency of the form of the verb ‘be’, in this case the contracted form ‘’m’, as parsed in figure 1. (Note that the sentences are given in tokenized form.)
(1) I ’m not a plaster saint .
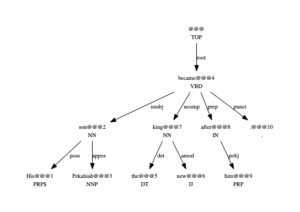
ncompis also used with the verb ‘become’, as in sentence (2), where “the new king” is an ncomp dependent of ‘become’, as parsed in figure 2.
(2) His son Pekahiah became the new king after him .
We believe that the introduction of ncomp has increased the consistency of the data used to train our parser. We believe that this further translates to a better application of the various dependency labels to the relations the parser will find in new data.
References
De Marneffe, M.-C. and Manning, C. D. (2008). Stanford typed dependencies manual. Technical report, Technical report, Stanford University.