Part 5. Named Entities
By Rodrigo Alarcón, Computational Linguist

We started this series of tutorials to show you how to call different modules of Codeq’s NLP API. So far, we have covered the following topics:
- Getting started and sending requests to the API.
- Calling NLP annotators for linguistic analysis.
- Using text classifiers to classify sentiments and emotions, and detect sarcasm in texts.
- Detecting abusive and harmful content from texts.
In this tutorial we will detail NLP modules related to the extraction and disambiguation of named entities from texts. Named entities refer to real-world entities, that is, things in the world, whether concrete or abstract (e.g., person, organizations, locations, etc.). The identification of named entities plays an important role in many NLP related use cases, for example in summarization of texts and monitoring of brands or products.
The complete list of modules we offer can be found in our documentation:
Codeq NLP API Documentation
Define a NLP pipeline and analyze a text
We initialize an instance of the Codeq Client and declare a pipeline containing the desired annotators. After that, we can send a text to the client and retrieve a Document object with a list of Sentences, where the information related to named entities is stored. To print a quick overview of the results, you can use the method document.pretty_print(), which we will explain in detail in the following sections.
For each annotator of this pipeline we are going to explain:
- the keyword (KEY) used to call the annotator,
- the attribute (ATTR) where the output is stored,
- the Output Labels of the annotator, if applicable.
Named Entity Recognition
This annotator extracts named entities from texts and provides the tokens of the entity, its type and its position in the tokenized sentence.
- KEY: ner
- ATTR: sentence.named_entities
Output Labels
- PER (person)
- LOC (location)
- ORG (organization)
- MISC (miscellaneous)
- DATE
- MONEY
- URL
- PHONE
- TWITTERNAME
- TRACKINGNUMBER
- AIRLINECODE
- AIRLINENAME
- AIRPORTCODE
- AIRPORTNAME
- EMOJI
- SMILIE
Named Entity Linking
Named Entity Linking (also called Named Entity Disambiguation) refers to the process of mapping a mention of an entity extracted from a text to unique entries of a knowledge base.
Given the high ambiguity of language, a named entity can have multiple names and a name can be linked to different named entities. Hence, the main goal of this annotator is to disambiguate the entity mentions in their textual contexts and identify a concrete referent, using Wikipedia and Wikidata as knowledge bases.
- KEY: nel
- ATTR: sentence.named_entities_linked
The output stored in the variable sentence.named_entities_linked is a list with the same number of entities found on the Named Entity Recognition module stored in the variable sentence.named_entities. If it is not possible to disambiguate a named entity (for example entities of type DATE, or cases where no referent is found on the knowledge base), then the corresponding element in the list sentence.named_entities_linked will be None.
Named Entity Salience
The goal of this annotator is to indicate the salience of named entities, that is, how relevant they are to the content of the input document. This annotator produces a tuple for each named entity, indicating if the entity is salient or not and its salience score.
- KEY: salience
- ATTR: sentence.named_entities_salience
Date Resolution
This annotator tries to resolve the specific dates of temporal expressions in natural language (e.g., next Friday, last Monday, etc.). The annotator takes as referent a relative date for the resolution, by default today. The output includes the date entity, its tokens span and the resolved timestamp.
- KEY: date
- ATTR: sentence.dates
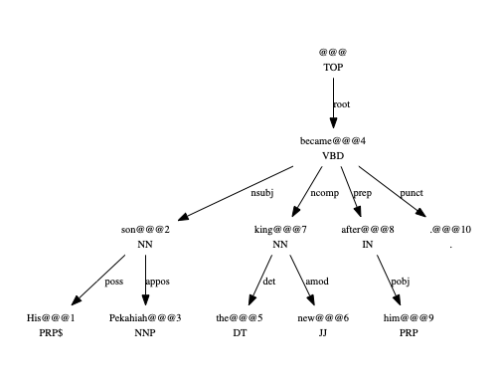
Coreference Resolution
A coreference occurs when two or more mentions in a text refer to the same entity using different words. For example, in the sentence:
“John is working today, he is at the office.”
The pronoun he refers to the entity John.
Our coreference resolution module tries to resolve pronominal coreferences, i.e., find references of entities for personal pronouns (he, she, him, her, etc.). The annotator produces a resolved coreference including the mention of the entity, its referent and a coreference chain with all the elements that point to the same entity.
- KEY: coreference
- ATTR: sentence.coreferences
As we can observe from the output above, a coreference element can contain a null mention if it is the first referent found in a text:
The referent_chain indicates the ids of the related coreference elements:
In the example above, the referent chain ids [‘01_00’, ‘00_07’] mean that all the related tokens, including the current mention, are:
Wrap Up
In this tutorial we described different modules related to the extraction and disambiguation of named entities. The code below summarizes how to call the annotators explained here and access their output.
Take a look at our documentation to learn more about the NLP tools we provide.
Do you need inspiration? Go to our use case demos and see how you can integrate different tools.
In our NLP demos section you can also try our tools and find examples of the output of each module.