Part 2. Linguistic features
By Rodrigo Alarcón, Computational Linguist

We started this series of posts to explain how you can call our NLP API to analyze your own documents.
- The first tutorial covered how to get started and send requests using our Python SDK.
- In this second tutorial we will show you different modules that can be applied to analyze texts at a basic linguistic level.
The complete list of modules we offer can be found in our documentation:
Codeq NLP API Documentation
Define a Pipeline
First, we will import the Codeq Client and define a pipeline containing different linguistic annotators.
Analyze a text
We can call now the client, analyze a text and print a quick overview of the analyzed content:
The NLP API uses two main objects to store the output:
- A Document object is used to store global information about the text, for example the language, summary or key phrases, e.g., content that is not associated with specific sentences.
- A list of Sentence objects is encapsulated within the Document, where particular information pertinent to each sentence is stored, for example tokens or part of speech tags.
Let’s go through each of the linguistic annotators of the pipeline and see the specific output that they produce.
- Each annotator is called by a keyword (KEY), which we defined in the pipe variable above.
- For each annotator, the output is stored in specific attributes (ATTR) at the Document or Sentence levels.
Language Identification
This module is designed to identify the language in which pieces of text are written. Currently, we support the identification of 50 languages:

- KEY: language
- ATTR: document.language
- ATTR: document.language_probability
Tokenization
This module generates a segmentation of a text into words and punctuation marks. Tokens will be stored at both Document and Sentence levels.
- KEY: tokenize
- ATTR: document.tokens
- ATTR: sentence.tokens
Sentence Segmentation
This module generates a list of sentences from a raw text. Each sentence will contain by default its position, raw_sentence and tokens.
- KEY: ssplit
- ATTR: document.sentences
- ATTR: sentence.position
- ATTR: sentence.raw_sentence
- ATTR: sentence.tokens
Stopword Removal
This annotator removes common stop words from the text.
- KEY: stopword
- ATTR: sentence.tokens_filtered
Part of Speech Tagging
This module identifies the category of each word from a grammatical or syntactic standpoint (e.g., verbs, nouns, prepositions, etc.). That category is referred to as a part of speech (POS).
The output of our POS tagger corresponds to the list of tags used in the Penn Treebank Project.
There are two attributes to access the POS tags, the first one contains only a list of tags for each token, the second one is a string with both tokens and POS tags in the format “token/POS”.
- KEY: pos
- ATTR: sentence.pos_tags
- ATTR: sentence.tagged_sentence
Lemmatization
This module identifies the appropriate lemma or canonical form of the words in a sentence. For example, conjugated verbs will be displayed in their infinitive form (are and is become be).
- KEY: lemma
- ATTR: sentence.lemmas
Stemming
The goal of this annotator is to reduce inflectional forms of a word to a common base form. For example the words connection, connections, or connecting should be converted to the base form connect.
- KEY: stem
- ATTR: sentence.stems
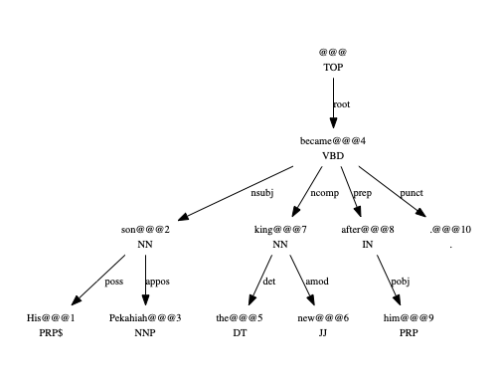
Dependency Parser
This annotator analyzes every word in a sentence and assigns it to a head node (another word in the same sentence) with a syntactic relation. The labels given to each relation of head and dependent reflect syntactic relations that exist between those words; for example, if a verb has a noun phrase as a subject, the relation of the verb to the head noun of its subject is given the label nsubj.
For all but one word in the sentence, its head will be another word in the same sentence; the exception has the artificial “root” node as its head.
Dependencies are stored in 3-tuples consisting of: head, dependent and relation. Head and dependent are in the format “token@@@position“. Positions are 1-indexed, with 0 being the index for the root.
The output of our Dependency Parser uses the labels for grammatical relations from the Stanford Dependencies.
- KEY: parse
- ATTR: sentence.dependencies
Chunker
Finally, the chunker annotator groups some of the words of a sentence into relatively small, non-overlapping groups to represent grammatically and/or semantically significant components. Common chunks include for example grouping a determiner with its noun, e.g., “tall person”, or an auxiliary verb with its verb, e.g., “will leave”.
The output of our Chunker uses the labels for chunk types from CONLL 2000.
- KEY: chunk
- ATTR: sentence.chunks
- ATTR: sentence.chunk_tuples
The variable sentence.chunks represents the groups of words and their label in a convenient format, e.g., “[NP This model]”. There is also another variable sentence.chunk_tuples where the chunks are stored as tuples indicating the chunk label, tokens and positions of the tokens:
Wrap Up
In this post we wanted to show some of the linguistic annotators of our NLP API, the pipeline keys you can use to call them, as well as the attributes where their output is stored. The following code snippet resumes the workflow explained above:
Take a look at our documentation to learn more about the NLP tools we provide.
Do you need inspiration? Go to our use case demos and see how you can integrate different tools.
In our NLP demos section you can also try our tools and find examples of the output of each module.