By Rodrigo Alarcón, Computational Linguist
Introduction
At Codeq, we are working on the development of an extensive suite of Natural Language Processing modules that we offer to third parties via our API. One of the main problems we recurrently came across during the development of different NLP modules is the availability and quality of annotated data that we can use to train our machine learning models.
Ideally, one would just need to search for the correct dataset and use it out of the box to develop a new model, tune its architecture and obtain state of the art results. That is just a naive expectation. The truth is that linguistic data annotation for NLP, or data labelling for ML, is commonly one of the hardest and most time consuming challenges ML practitioners face.
In a previous post, we have detailed some of the linguistic phenomena we faced while annotating sentences for training a machine learning model to extract task requests from emails. In this blog post, we want to give a brief overview of similar issues in the field of semantic similarity and emphasize the importance of quality in linguistic annotation.
What is Natural Language Annotation?
The annotation of language data has its roots in the development and testing of linguistic theories using corpus linguistics, where researchers were focused on compiling large amounts of language data in textual or spoken form and adding metadata to describe different language utterances (Ide, 2017).
Later, the resources that were used for linguistic studies began to be used in the field of Natural Language Processing, as this field relies extensively on the use of linguistically-annotated text and speech corpora to train, develop and evaluate human language technologies (Pustejovsky et al, 2012; Ide, 2017).
On every machine learning project related to NLP, there is the need to obtain training data with good human annotations. In order to develop efficient algorithms, the annotated data needs to be accurate, concise and representative. Hence the main problem: a ML model can only be as good as the training data it is based on.
“Having a good annotation scheme and accurate annotations is critical for machine learning that relies on data outside of the text itself. The process of developing the annotated corpus is often cyclical, with changes made to the tagsets and tasks as the data is studied further.” (Pustejovsky et al, 2012).
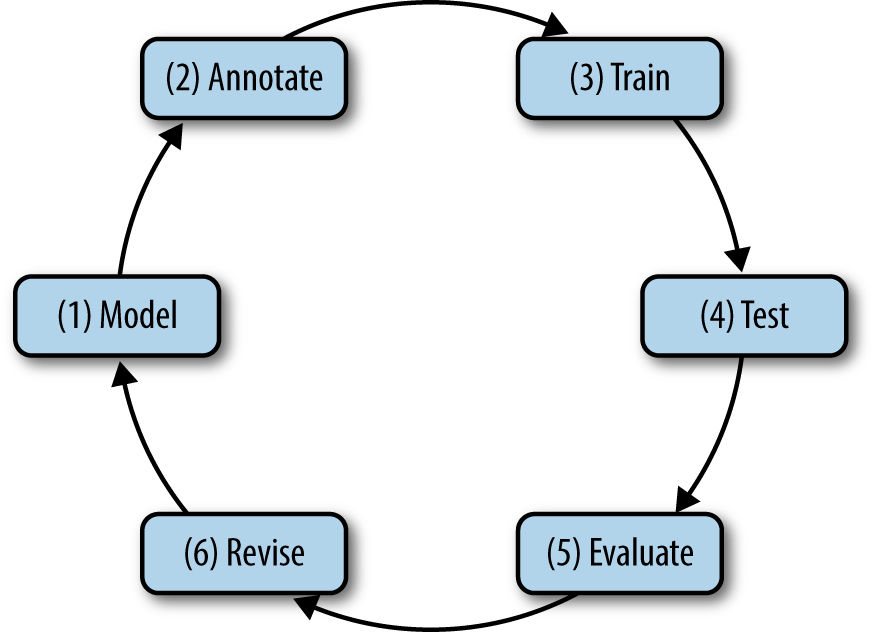
The MATTER cycle for linguistic annotation: Model, Annotate, Train, Test, Evaluate, Revise (Pustejovsky et al, 2012)
In this sense, Natural Language Annotation can be seen as a set of standard practices involving not only the tagging of specific information on a dataset, but also the linguistic study of the data, the revision and evaluation of the annotations, the measure of the agreement between the annotators and the observation of the output after training and testing the model itself.
However, such a set of good practices is not always easy to implement. The availability of data, the resources available to tag information or the time invested to compile an annotation scheme, all are challenges to overcome. At the end, unfortunately, it is not uncommon to face annotation inconsistencies when exploring an existing annotated dataset.
Semantic Similarity: a case study
Let’s consider the field of Semantic Textual Similarity (STS): a process that intends to measure the semantic equivalence between two sentences (Agirre et al, 2012).
The development of algorithms to detect the semantic similarity between texts has become a major interest in recent years, mainly due to its applicability in a wide range of technologies: recommendation systems, semantic search engines, text clustering, finding similar items (products, news), etc.
There is an ongoing set of parallel tasks in NLP conferences related to STS, which have included different human annotated datasets over the years, ranging from image captions, news headlines, tweets and user forums (a good overview of the different datasets can be found in the STS Wiki). The annotated data mainly includes a score to indicate the semantic relatedness between two sentences in the range of 0 to 5, where:
- 0 = highly non-related
- 5 = highly related
One of those parallel tasks was SICK (Sentences Involving Compositional Knowledge) (Marelli et al, 2014; Bentivogli et al, 2016), that included a dataset derived from other STS tasks containing image and video descriptions. The original descriptions were normalized and expanded to obtain up to three new sentences, where a rule for the expansion was the transformation of a sentence into its negative form:
| Original Sentence | Expanded Sentence |
|---|---|
| Two women are dancing | Two women are not dancing |
| A man is playing flute | There is no man playing flute |
Example of expanded sentences using a negation form
In this expansion of negative forms, we can find a prominent set of inconsistencies in the similarity scores assigned manually. On an exploratory analysis of around 9,000 pairs of sentences, we find a total of 1,915 pairs where one sentence includes a sign of negation, basically the presence of the tokens “no” or “not”. We then use a simple set of rules to eliminate negation forms, trying to revert the expanded sentence to its original form. The following function is used to revert the expanded sentence:
def clean_sentence(sentence): sentence = sentence.replace('There is no ', '') sentence = sentence.replace('There is not ', '') sentence = sentence.replace('There are no ', '') sentence = sentence.replace('There are not ', '') sentence = sentence.replace('A ', '') sentence = sentence.replace('The ', '') sentence = sentence.replace(' is ', ' ') sentence = sentence.replace(' no ', ' ') sentence = sentence.replace(' not ', ' ') return sentence
In this way, we were able to revert a total of 759 pairs of sentences. In other words, the sentences were exactly the same after removing the patterns shown above. We found a significant divergence on the similarity scores assigned manually, that went from a minimum score of 2.4 (barely similar) to a max score of 4.8 (highly similar).
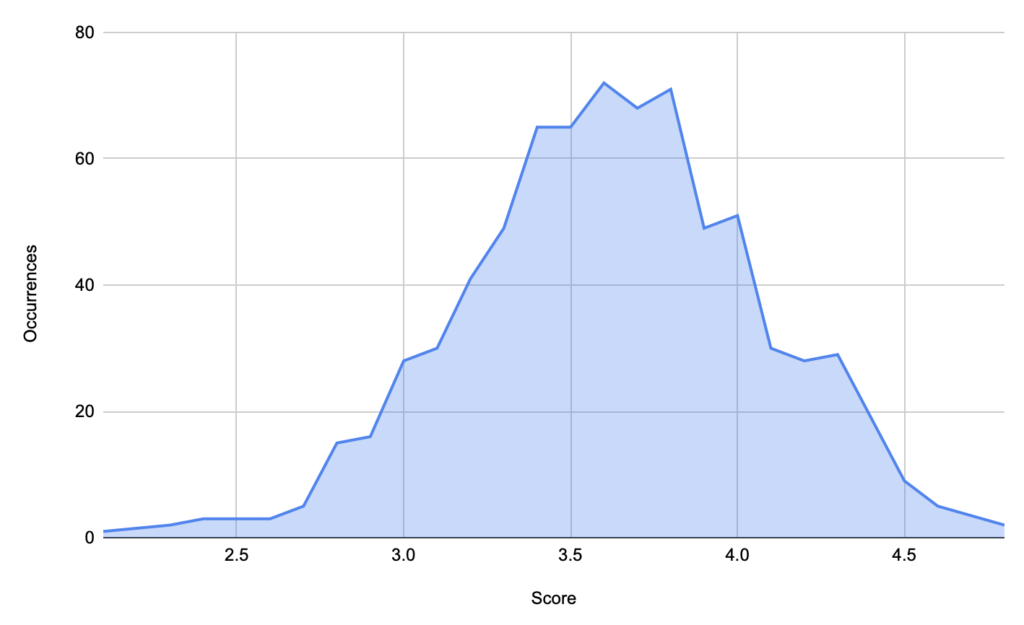
Divergence of scores on negation sentences on the SICK dataset
Even if the mean of the scores lies around 3.5, as we can see on the image above, there is a visible human annotation disagreement on how to score sentences that follow exactly the same negation pattern. We would expect the same similarity score for each pair of sentences that differ only by negation. The following table shows some examples of the scores assigned:
| score | Sentence 1 | Sentence 2 |
| 2.4 | A man is playing two keyboards | There is no man playing two keyboards |
| 2.7 | A woman is slicing a fish | There is no woman slicing a fish |
| 3.6 | A man is not cutting a potato | A man is cutting a potato |
| 3.9 | There is no woman slicing a potato | A woman is slicing a potato |
| 3.2 | A woman is playing a flute | The woman is not playing the flute |
| 4.2 | A man is playing a flute | A man is not playing a flute |
| 4.5 | A dog is playing with a toy | There is no dog playing with a toy |
| 4.8 | There is no man playing soccer | A man is playing soccer |
Examples of inconsistencies on manually scored sentences on SICK dataset
Finally, we consider that this divergence on the human annotations will influence the performance of any ML model trying to learn a representation of sentences sharing the same linguistic form, where the labels assigned manually are introducing a subjacent form of noise.
Conclusions
In this post, we wanted to emphasize the importance of Natural Language Annotation on the development of NLP technologies. At Codeq, the annotation of linguistic data for training quality Machine Learning models is one of our core tasks when developing the models that we offer in our NLP API.
Are you interested in learning more about our NLP technology? Take a look at our API documentation and sign up to start experimenting with our tools.
References
Pustejovsky, J., & Stubbs, A. (2012). Natural Language Annotation for Machine Learning: A guide to corpus-building for applications. O’Reilly Media, Inc.
Agirre, E., Cer, D., Diab, M., & Gonzalez-Agirre, A. (2012). Semeval-2012 task 6: A pilot on semantic textual similarity. In SEM 2012: The First Joint Conference on Lexical and Computational Semantics–Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation (SemEval 2012) (pp. 385-393).
Marelli, M., Menini, S., Baroni, M., Bentivogli, L., Bernardi, R., & Zamparelli, R. (2014). A SICK cure for the evaluation of compositional distributional semantic models. In LREC (pp. 216-223).
Marelli, M., Bentivogli, L., Baroni, M., Bernardi, R., Menini, S., & Zamparelli, R. (2014). Semeval-2014 task 1: Evaluation of compositional distributional Semantic Models on Full Sentences through Semantic Relatedness and Textual Entailment. In Proceedings of the 8th international workshop on semantic evaluation (SemEval 2014) (pp. 1-8).
Bentivogli, L., Bernardi, R., Marelli, M., Menini, S., Baroni, M., & Zamparelli, R. (2016). SICK through the SemEval glasses. Lesson learned from the evaluation of compositional distributional semantic models on full sentences through semantic relatedness and textual entailment. In Language Resources and Evaluation, 50(1), 95-124.
Ide, N. (2017). Introduction: The handbook of linguistic annotation. In Handbook of Linguistic Annotation (pp. 1-18). Springer, Dordrecht.