By Rodrigo Alarcón, Computational Linguist
An exploratory analysis showing how Semantic Roles can be used to extract Knowledge-Rich Contexts. See it in action here: labs.codeq.com/semantic_roles_cord_19
One of the most recent modules we have developed at Codeq NLP API is the Semantic Role Labeler. The goal of this module is to understand the underlying semantics of natural language sentences by identifying their main events and participants, and classifying the different types of relations between them (Davidson, 1967; Parsons, 1990).
In the extraction of Semantic Roles, events are usually called predicates, while the participants are known as the arguments of a given predicate. In addition, arguments can denote specific types of relations, for example they can be an Agent, a Patient or a Location in relation to the predicate.
Let’s consider the following example:

In this sentence, the predicate reported is associated with the arguments Patient, Location and Temporal, which, in general terms, can be helpful to understand the WHO, WHERE and WHEN entities related to that specific predicate.
Semantic Roles can be useful in many Natural Language Processing tasks, including Information Extraction, Text Summarization and Question Answering. Nowadays, the COVID-19 pandemic has exposed the importance of NLP in Biomedicine, in order to automatically analyze the growing resource of scientific papers about coronavirus research and extract useful information to discover drugs, symptoms or treatments related to the disease.
In this post, we want to show an exploratory analysis of extracting Semantic Roles from CORD-19: The Covid-19 Open Research Dataset (Wang et. al., 2020). Specifically, we want to describe how Semantic Roles can be used to automatically extract Knowledge-Rich Contexts, i.e., sentences useful to describe the meaning of concepts and semantic relations among them.
Knowledge-Rich Contexts
The extraction of Knowledge-Rich Contexts is a known task in the field of Information Extraction. It aims to identify textual fragments containing explicit information about attributes, characteristics and semantic relations of concepts, information that can be used as a starting point to formulate definitions, to mine semantic relations and to elaborate specialized dictionaries, ontologies and knowledge bases. (Hearst 1992; Meyer 2001; Snow et. al., 2005; Auger & Barrière 2008).
“Within large corpora of texts, Knowledge-Rich Contexts (KRCs) are a subset of sentences containing information that would be valuable to a human for the construction of a knowledge base.” (Barrière, 2004)
Knowledge-Rich Contexts are usually expressed by means of recurrent lexical-syntactic patterns. One of those patterns are verbal structures that work as connectors between a term and its definition, and could also be linked to specific sorts of semantic information (Alarcón et. al., 2009a, 2009b).
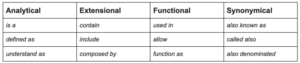
Examples of verbal patterns associated with specific types of definitions (Alarcón et. al., 2009b).
The pattern is a (verb to be + article) is among the most common lexico-syntactic structures associated with analytical definitions, which tend to indicate a relation of hypernym/hyponym and introduce the most basic structure to describe a term. Usually, they constitute a form such as:
X is a Y which Z
Where X is the term being defined, Y the hypernym, i.e., the conceptual class that X belongs to, and Z the characteristics that differentiates X from other members of the same class. A simple example would be:

Semantic Roles for the extraction of Knowledge-Rich Contexts
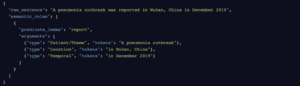
Now, how can Semantic Roles be used for the extraction of Knowledge-Rich Contexts? Let’s extrapolate the last example and consider the representation that is generated by the Semantic Role Labeler of our NLP API (you can try it yourself in our demo section):

From this example, we can observe the following:
- the term X (COVID-19) corresponds to the argument Patient/Theme,
- the lemmatized lexical pattern be is identified as the Predicate,
- the class Y (infectious disease) is contained within the argument Instrument/Beneficiary,
- and the specific characteristics Z (caused by…) are identified by its corresponding semantic role introduced by the Predicate cause
This segmentation corresponds in general terms to the common structure of analytical definitions, which simplifies not only the extraction of Knowledge-Rich Contexts but also the automatic extraction of its constituents. In addition, the extraction of Semantic Roles can be very useful for correctly segmenting contexts with more stylistic variations. Consider the following hypothetical examples:



As you can observe, the Semantic Role Labeler is correctly segmenting both the term (COVID-19) and its definition (as an infectious disease…) in variations of a similar utterance with distinct verbal patterns. Besides, the Semantic Role Labeler is able to catch the subjacent relation between the term and its definition in relation to the predicate: in all cases they correspond to the arguments Patient/Theme (term) and Instrument/Beneficiary (definition).
Extracting Knowledge-Rich Contexts from CORD-19
We developed a very simple methodology to perform an exploratory analysis of abstracts of the CORD-19 dataset (release from 2020–10–15) and extract candidates of Knowledge-Rich Contexts containing the pattern is a:
- We compiled a corpus consisting of all sentences of all abstracts analyzed with the Semantic Role Labeler of our NLP API.
- On the extracted sentences, we kept only those containing arguments where the predicate was the verb to be in present form (is, are) and containing at least one semantic role with both arguments Patient/Theme and Instrument/Beneficiary.
- We applied a couple syntactic rules as filters to avoid false positives, e.g., if the argument Patient/Theme was only one single token, it should be pos-tagged as a Noun; the argument Instrument/Beneficiary should start with any of the tokens: [“a”, “an”, “the”, “one”].
As result, we analyzed 79,958 abstracts and were able to extract 686,995 sentences containing semantic roles. From those sentences, 255,111 contained an occurrence of the lemma be. Finally, 7,728 sentences were extracted as candidates of Knowledge-Rich Contexts after applying the filters mentioned above.
Exploring the results
In order to showcase the extracted Knowledge-Rich Contexts candidates, we developed a web app using Streamlit that can be found at:
labs.codeq.com/semantic_roles_cord_19
Here we want to share a couple interesting search results of different queries.
1. Sentences containing the term “protein” as Patient/Theme (e.g., proteins being described):

2. Sentences containing the query “treatment for” as Instrument/Beneficiary (e.g., concepts that are possible being described as treatments):



Final Words
Semantic Roles are a powerful tool for Information Extraction. The results that we can find in the app described above show that a simple methodology on top the extraction of Semantic Roles can lead to the discovery of useful information about specialized terms and semantic relations between them.
Our Semantic Role Labeler is based on other powerful NLP modules we have developed at Codeq, including a POS-Tagger and a Dependency Parser. These modules can be easily combined to analyze your own texts using our NLP API. If you are interesting, please give it a try.
Are you a domain expert or a data scientist working on analyzing CORD-19 research papers and want to take a deeper look at the results we generated? Then please contact me at: rodrigo@codeq.com
Side note: if you want to showcase your ML models or any data related output, you need to take a look at streamlit.io. It’s an amazing tool to showcase your work!
References
Alarcón R., Sierra, G. & Bach, C. (2009a). ECODE: A Definition Extraction System. In Human Language Technology. Challenges of the Information Society. Vetulani, Z. &. Uzkoreit, H. (eds.). Lecture Notes in Computer Science 5603. Berlin-Heidelberg, Springer-Verlag. 382–391.
Alarcón R., Sierra, G. & Bach, C. (2009b). Description and Evaluation of a Definition Extraction System for Spanish Language. In 1st International Workshop on Definition Extraction. Sierra, G., Pozzi, M. & Torres, J.M. (eds.). Stroudsburg PA, Association for Computational Linguistics. 7–13.
Auger, A., & Barrière, C. (2008). Pattern-based approaches to semantic relation extraction: A state-of-the-art. Terminology, 14(1), 1.
Barrière, C. (2004, May). Knowledge-rich contexts discovery. In Conference of the Canadian Society for Computational Studies of Intelligence (pp. 187–201). Springer, Berlin, Heidelberg.
Davidson, D. (1967), The Logical Form of Action Sentences. In The Logic of Decision and Action. N. Rescher (ed.). Pittsburgh: University of Pittsburgh Press.
Hearst, M. A. (1992). Automatic acquisition of hyponyms from large text corpora. In Coling 1992 volume 2: The 15th international conference on computational linguistics.
Meyer, I. (2001). Extracting knowledge-rich contexts for terminography. Recent advances in computational terminology, 2, 279.
Parsons, T., (1990). Events in the Semantics of English. Cambridge, MA: MIT Press.
Snow, R., Jurafsky, D., & Ng, A. Y. (2005). Learning syntactic patterns for automatic hypernym discovery. In Advances in neural information processing systems (pp. 1297–1304).
Wang, L. L., Lo, K., Chandrasekhar, Y., Reas, R., Yang, J., Eide, D., … & Mooney, P. (2020). CORD-19: The Covid-19 Open Research Dataset. ArXiv.