By Paulo Malvar, Chief Computational Linguist
A realization
The rise in interest in research and development of tools to help detect and combat the growth of online abusive behavior and discourse is clearly observable by the amount of academic work produced over the past two decades.
When I started getting ready to work on developing Codeq’s abuse detection module, I had to spend a considerable amount of time reviewing as much existing literature on the topic as possible. Today, when I was going over all the papers that I had gathered to prepare for this post, I realized that, whereas in the early 2000’s and 2010’s there were some papers scattered here and there, there was a clear uptick in the number of papers published that started right around 2015 and 2016 (see the Reference section of this post for a representative collection).
Moreover, since 2017 the number of conferences and workshops dedicated to researching abusive online behavior has been growing. In 2017 the First Workshop on Abusive Language Online took place in Vancouver, in 2018 First Workshop on Trolling, Aggression and Cyberbullying, and in 2019 the 13th International Workshop on Semantic Evaluation hosted a Shared Task on Multilingual Detection of Hate (HatEval).
What’s the big deal?

To understand why the task of automatic detection of abusive speech (or aggressive, toxic, harmful or hateful speech, however you want to put it) is important, one needs to understand the effects this type of interactions have.
As Risch & Krestel (2018) clearly state:
“The opportunity to articulate opinions and ideas online is a valuable good: It is part of the freedom of expression […]. However, aggressive and/or hateful posts can disrupt otherwise respectful discussions. Such posts are called “toxic”, because they poison a conversation so that other users abandon it.” (150)
Whatever the specific motivations different people have to engage other people in an abusive verbal manner, the disruption this type of encounters causes is undeniable. Even if people victimized by this type of behavior don’t abandon conversations, which they usually do, it sets an ever more aggressive and polarizing tone that prevents healthy conversations from taking place.
The issue becomes even more critical and serious, when abusive statements go beyond being offensive and insulting to become instances of hate speech. Despite the elusive and fluid nature of hate speech –as exemplified by Fortuna and Nunes (2018), where they collect a sample of differing definitions from academic literature, public institutions and corporate entities–, this dangerous manifestation of verbal abuse is a poison that rots implicit and explicit social contracts and norms and ultimately inspires and incites violence against certain groups.
If any of this wasn’t reason enough to take this phenomenon seriously, as many online publications and social networking platforms know, there’s a monetary harm that is invariably attached to this type of behavior. User content moderation, when not outright impossible due to the overwhelming amount of content daily produced, is very costly.
As it’s becoming painfully clear, even big social network corporations, who can directly or indirectly hire thousands of content moderators, are struggling to keep up with the pace at which abusive interactions are taking place.
If this is the case for large actors, how then can small and independent content creators trying to grow online communities be expected to effectively deal with this titanic task?
That’s right, they can’t. That’s exactly why automatic and/or machine-aided content moderation are an urgent necessity.
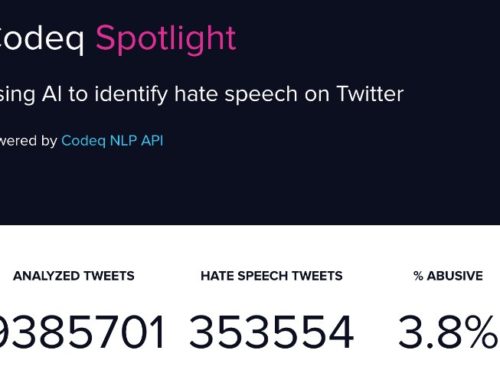
In this post I would like to introduce you to Codeq’s abuse classifier, the latest addition to Codeq NLP API.
Codeq’s Abuse Detection Module
Since the uptick in interest in academic research that I alluded to in the introduction to this post, a handful of corpora have been made available to the research and development community. Below is a table that summarizes and gives details about the nature and size of the already existing corpora that I explored when I started working on this project.

The first problem I encountered while specifically processing Founta et al., 2018 is that, given the nature of the content of the data, many of the referenced tweets had been deleted so out of the original 99800 tweets I was able only to retrieve 2544.
The second and main problem I encountered is that not only does each corpus use its own set of labels but after exploring the datasets it became apparent that corpus creators had used different definitions for the overlapping labels. In practice, what this meant is that I needed to manually review and relabel each corpus in order to normalize the annotations.
After this long and tedious process and after gathering more data from a variety of online sources, which I also labeled manually according to the normalized set of labels I finally settled on (see below for the list of labels I ended up using), I was able to compile a corpus of 90910 entries.
This corpus was subsequently partitioned into three datasets, training, development and test, with 81818, 4546 and 4546 entries respectively.
Types of abuse

Abusive behavior in life presents itself in many forms, and its online manifestation is no different.
Building a classifier that labels inputs as abusive or non-abusive would be useful but it would not really help discriminate among just plainly offensive utterances and really hurtful instances of hate speech or threatening behavior. Having an overly granular label set would not be easy to maintain and being able to gather a representative enough number of entries for some categories would be in practice challenging if not unfeasible.
Below is a list of labels that Codeq’s abuse classifier supports and that I considered provided a good balance between the needed level of granularity and the desirable level label representativeness.
- Offensive: The abuse classifier labels as offensive sentences that contain profanity or that could be perceived as disrespectful.
- Obscene/scatologic: Sentences containing sexual content or references to bodily excretions are labeled by the abuse classifier as belonging to this category.
- Threatening/hostile: This category is assigned to sentences that can be perceived as conveying a desire to inflict harm to somebody.
- Insult: The abuse classifier labels sentences containing insults as belonging to this category.
- Hate speech/racist: As mentioned above, the definition of hate speech is kind of elusive (see Fortuna and Nunes, 2018: 4). My intent when I worked on training the abuse classifier was for it to learn that hate speech is textual material that attacks a person or a groups of people based on their actual or perceived race, ethnicity, nationality, religion, sex, gender indentity, sexual orientation or disability, and that ultimately incites hatred and some type of violence against them.
The label distribution of the final corpus I compiled is summarized on the chart below.
Please note that except for the Non-abusive category, which is mutually exclusive, the rest of categories are complementary. Thus, sentences can contain one or more forms of abuse.

The classifier
From an architectural point of view, the abuse classifier is a multilabel classifier with five binary outputs, each of which assigns inputs as belonging or not to each supported type of abuse.
This classifier is implemented using the Keras library and TensorFlow as its backend.
Internally the classifier was designed to model inputs in two ways by jointly analyzing character sequences using a 1D convolutional neural network layer with global max pooling and sequences of words using a bidirectional long short-term memory with attention.
This setup enables the classifier to not only see sequences of tokens but also chunks of characters, which allows it to overcome word obfuscation techniques by character replacement used to disguise abusive terms, such as: “a$$hole”, “b1tch” or “ni33er”.
Evaluation
In order to test the performance of the trained abuse detection module I experimented with different probability thresholds for each category to ensure high precision with as high recall as possible.
The results obtained for the test dataset are as follows:






As it is clear from these results, the performance for each category varies in its degree of precision and recall. However, my intent, as mentioned above, was to maximize both metrics but with a bias towards precision, that is, a bias towards minimizing the number of false positives as much as possible.
I believe this is important because it reduces the amount of noise humans would have to sort through while reviewing the outputs produced by the classifier. With the help of humans who use this classifier, it’ll be retrained with reported false negatives and over time it’ll learn new abusive structures and patterns that will increase its confidence when classifying inputs as containing one or more types of abuse.
Final words
The interest in combating online abusive behavior has increased in recent years as this behavior has become more prevalent and destructive. In this post, I discussed this matter and how problematic it is, as well as introduced you to Codeq’s contribution to solve this societal issue.
I invite developers and content creators who are growing online communities to give it a try. For more information about this and other tools included in Codeq NLP API, please visit our website.
References
Aroyehun, S. T., Gelbukh, A., 2018. (2018). “Aggression Detection in Social Media: Using Deep Neural Networks, Data Augmentation, and Pseudo Labeling”. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying. pp. 90–97.
Basile, V., Bosco, C., Fersini, E., Nozza, D., Patti, V., Rangel, F., et al. (2019). “Semeval-2019 task 5: Multilingual Detection of Hate speech against immigrants and women in Twitter”. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying. pp. 54–63.
Burnap, P., & Williams, M. L. (2015). “Cyber Hate Speech on Twitter: An Application of Machine Classification and Statistical Modeling for Policy and Decision Making”. In Policy & Internet. Vol. 7 (2), 223–242.
Chau, M., & Xu, J. (2007). “Mining communities and their relationships in blogs: A study of online hate groups”. In International Journal of Human-Computer Studies. Vol. 65 (1). pp 57–70.
Davidson, T., Warmsley, D., Macy, M., & Weber, I. (2017). “Automated Hate Speech Detection and the Problem of Offensive Language”. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media (ICWSM 2017). pp. 512–515.
de Gibert, O., Perez, N., García-Pablos, A., & Cuadros, M. (2018). “Hate Speech Dataset from a White Supremacy Forum”. In Proceedings of the Second Workshop on Abusive Language Online. pp. 11–20.
Founta, A.-M., Djouvas, C., Chatzakou, D., Leontiadis, I., Blackburn, J., Stringhini, G., et al. (2018). “Large Scale Crowdsourcing and Characterization of Twitter Abusive Behavior”. In Proceedings of the 11th International Conference on Web and Social Media. pp. 491–500.
Fortuna, P., & Nunes, S. (2018). “A Survey on Automatic Detection of Hate Speech in Text”. ACM Computing Surveys. Vol. 51 (4). pp. 1–30.
Gambäck, B., & Kumar Sikdar, U. (2017). “Using Convolutional Neural Networks to Classify Hate-Speech”. In Proceedings of the First Workshop on Abusive Language Online. pp. 85–90.
Gao, L., & Huang, R. (2017). “Detecting Online Hate Speech Using Context Aware Models”. In Proceedings of the 2017 EMNLP Workshop on Natural Language Processing meets Journalism. pp. 260–266.
Greevy, E., & Smeaton, A. F. (2004). Text Categorisation of Racist Texts Using a Support Vector Machine. Presented at the Proceedings of the th annual international ACM SIGIR conference on Research and development in information retrieval. pp. 468–469.
Kwok, I., & Wang, Y. (2013). “Locate the Hate: Detecting Tweets against Blacks”. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence. pp. 1621–1622.
Reynolds, K., Kontostathis, A., & Edwards, L. (2011). “Using Machine Learning to Detect Cyberbullying”. In Proceedings of the Tenth International Conference on Machine Learning and Applications. pp. 241–244.
Risch, J., Krestel, R., 2018. (2018). “Aggression Identification Using Deep Learning and Data Augmentation”. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying. pp. 150–158.
Risch, J., & Krestel, R. (2020). “Toxic Comment Detection in Online Discussions”. In Deep Learning Based Approaches for Sentiment Analysis. pp. 1–27.
Sharma, S., Agrawal, S., & Shrivastava, M. (2018). “Degree based Classification of Harmful Speech using Twitter Data”. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying. pp. 106–112.
Schmidt, A., & Wiegand, M. (2017). “A Survey on Hate Speech Detection using Natural Language Processing.” In Proceedings of the Fifth International Workshop on Natural Language Processing for Social Media. pp. 1–10.
van Aken, B., Risch, J., Krestel, R., & Löser, A. (2018). “Challenges for Toxic Comment Classification: An In-Depth Error Analysis”. In Proceedings of the Second Workshop on Abusive Language Online. Vol. 1809, pp. 33–42.
Warner, W., & Hirschberg, J. (2012). “Detecting hate speech on the world wide web”. In Proceedings of the Second Workshop on Language in Social Media, Association for Computational Linguistics. pp. 19–26.
Waseem, Z. (2016). “Are You a Racist or Am I Seeing Things? Annotator Influence on Hate Speech Detection on Twitter”. In Proceedings of the First Workshop on NLP and Computational Social Science. pp. 138–142.
Waseem, Z., Davidson, T., Warmsley, D., & Weber, I. (2017). “Understanding Abuse: A Typology of Abusive Language Detection Subtasks”. In Proceedings of the First Workshop on Abusive Language Online. pp. 78–84.
Waseem, Z., & Hovy, D. (2016). “Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter”. In Proceedings of the NAACL Student Research Workshop. pp. 88–93.
Wulczyn, E., Thain, N., & Dixon, L. (2016). Ex Machina: Personal Attacks Seen at Scale.
Xu, J.-M., Jun, K.-S., Zhu, X., & Bellmore, A. (2012). “Learning from Bullying Traces in Social Media”. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics Human Language Technologies, Association for Computational Linguistics. pp. 656–666.
Yin, D., Xue, Z., & Hong, L. (2009). “Detection of Harassment on Web 2.0”. In Proceedings of Content Analysis in the WEB 2.0 Workshop. pp. 1–7.
Zhou, Y., Reid, E., Qin, J., Chen, H., & Lai, G. (2005). “US Domestic Extremist Groups on the Web: Link and Content Analysis”. In IEEE Intelligent Systems. Vol. 20(5). pp 44–51.