By: Paulo Malovar, Chief Computational Linguist
Late 2017 I wrote an article discussing the project we at Codeq were at the time working on: Courier.
Courier was an email processing system that analyzed incoming email messages to extract relevant information and summarize the content of emails. As an email client with magic NLP powers, Courier’s main objective was to ease the burden of information overflow in the form of email by, without the need of opening emails messages, presenting relevant bits of information and informative short summaries condensing the meaning of those messages.
Internally, Courier was powered by a myriad of NLP modules, some of which we discussed in previous posts (Pragmatics: The Last Frontier, Courier’s Botmail Field Extractor, Extracting Tasks from Emails: First Challenges), which among other things: classified incoming messages as being commercial or personal email, analyzed and extracted tasks, questions and commitments, and generated extractive summarizes that preserved the coherence of the original message.
During the time Courier was available on the Apple App Store, this brilliantly orchestrated system of NLP tools processed and generated summaries for more than 22 million messages and extracted almost 500 thousand tasks for the 500 users we captured worldwide.

In 2019, we at Codeq decided it was time to let Courier go. However, all the knowledge we gathered, all the lessons we learned, and most importantly all the cool stuff that we had built was well and alive.
We decided it was time to start offering all the tools that we had built during Courier’s development in a new way.
Today I would like to present to you…
Codeq NLP API
Codeq NLP API is the new platform that we have created to offer access to all the technology we built for Courier plus an increasing number of NLP modules that we are carefully crafting.
This NLP API features all the basic low level modules that any NLP practitioner or student may need: language identification, tokenization, sentence splitting, stopword removal, stemming, true casing, POS-tagging, lemmatization, dependency parsing, chunking, named entity recognition, and coreference resolution.
We have recently added, though, a module that we’re very proud of: semantic role labeling. This is a fantastic addition to our set of low level NLP tools that allows for a deeper semantic understanding of the underlying meaning of sentences.
However, the fun does not stop there. We at Codeq recognize that NLP practitioners are not the only ones who would benefit from a comprehensive set of tools to unlock meaning and understanding from unstructured text.
Codeq NLP API also features more high level NLP modules that will empower non-NLP versed developers to build powerful applications with them. We are planning on writing specific posts dedicated to each of these powerful high level modules, but for the time being let it suffice this succinct description of each of them:
Named Entity Linking: This module links and disambiguates recognized named entities to WikiData’s knowledge base. This is a formidable tool that allows developers to ID specific entities found in text and attach real world information to each of them.
Named Entity Salience: This module ranks named entities found in text according to their relevance with respect to the meaning of the text where they have been recognized.
Speech Act Classifier: This module labels sentences according to their illocutionary force. In other words, their intent and their effect in the world
Question Classifier: This module labels questions present in text according to the type of information that they request.
Sentiment Classifier: This module classifies sentences according to the positive or negative sentiment(s) they convey.
Emotion Classifier: Sentiment classification is a task that provides coarse understanding of attitudes and states of mind expressed in text. Emotion classification is a more powerful extension that unlocks more fine-grained understanding of those attitudes and states of mind.
Sarcasm Classifier: Ignoring the fact that humans convey their attitudes and states of mind in indirect ways is a common oversimplification in the world of NLP. Our sarcasm classifier tries to identify instances of this type of indirect speech act that commonly shift the emotion and/or sentiment being expressed.
Summarization: This module identifies the most relevant sentences in a document and, while trying to preserve the coherence of the original text, generates a summary that condenses the meaning of the original document.
Sentence Compression: Sentence compression is a form of summarization or information condensation that, by analyzing the underlying syntactic structure of sentences, determines which constituents or phrases are dispensable and removes them while preserving the main meaning of sentences.
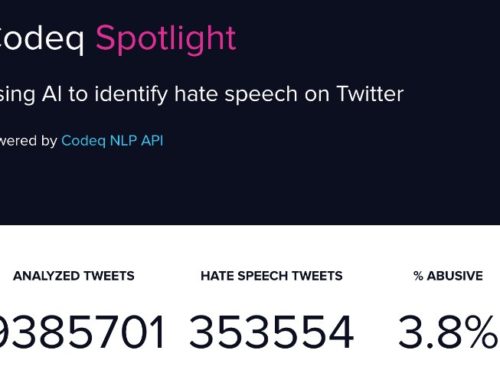
Abuse Classifier: This module, which is our latest addition, labels sentences according to whether they contain one or more types of abusive content, like insults, hate speech, threats, etc. In an era of extreme polarization and hyperconnectivity we believe this is an indispensable tool for content creators to manage their online communities.
The show must go on
In this post I have introduced Codeq NLP API and briefly discussed its capabilities, as well as the path that got us here. Courier was an awesome project that helped us introduce the world to the technologies Codeq is building.
But today Codeq is all about our NLP API. For more information, please visit our website. There you will be able to play around with all these tools and learn about specific use cases that showcase and exemplify powerful workflows that leverage the NLP modules that our API offers.
The show must go on!!